wordle-lora-rl
Wordle-RL: Training a Language Model to Play Wordle with Reinforcement Learning on Apple Silicon
![]()
This project is an exploration into training a Large Language Model (Gemma-3 4B-it) to play the game of Wordle using Reinforcement Learning (RL) with LoRA. The entire training and inference pipeline is optimized to run locally on Apple Silicon using the MLX framework.
The primary goals were to gain hands-on experience with RL, understand the challenges and hardware constraints of local training, and compare RL techniques to traditional Supervised Fine-Tuning (SFT).
This is not an officially supported Google product. This project is not eligible for the Google Open Source Software Vulnerability Rewards Program.
This project is intended for demonstration purposes only. It is not intended for use in a production environment.
Table of Contents
- Why Wordle? The RL Challenge
- The Technology Stack: Why MLX?
- Getting Started
- Usage
- The Reinforcement Learning Strategy
- Results and Analysis
- Key Lessons Learned
- Further Reading
Why Wordle? The RL Challenge
What is Wordle?
If you are not familiar with wordle, the best way is to play a round: wordle-nyt.
Do we need RL?
While Wordle can be solved deterministically using algorithms based on information theory (as beautifully explained by 3Blue1Brown), it presents a fascinating and constrained environment for Reinforcement Learning.
An algorithmic approach typically works by:
- Maintaining a list of all possible secret words.
- Choosing a guess that maximizes the expected information gain (entropy), effectively splitting the remaining possibilities as evenly as possible.
- Filtering the list of possibilities based on the feedback and repeating the process.
This project takes a different approach: Can we teach a language model to develop a strategic policy for playing Wordle simply by rewarding good moves and penalizing bad ones? This makes it a perfect, self-contained problem for learning and applying RL concepts.
Lets look at this example where the secret word is “STARS”:
Played 'TARES', got feedback '---x✓'
Possible words remaining: 7 -> ['STARS', 'DRATS', 'BRATS', 'FRATS', 'PRATS', 'ARTIS', 'ROTAS']
Played 'FIORD', got feedback 'xxx✓x'
Possible words remaining: 1 -> ['STARS']
🎉 🎉 🎉 Congratulations! 'STARS' is the correct answer, after 3 plays!
The algorithmic version starts with the following assumptions: 1) we have a finite list of words (words_list) 2) we have a finite list of allowed guesses where (allowed_guesses <= words_list)
After each guess, we get feedback on the letter positions which allows us to keep only the possible guesses First, the word ‘TARES’ provides us with the maximum amount of information ~6.3 bits from that feedback, there are now 7 possible words remaining.
In order to guess which one of the 7, the idea behind the algorithm, is to propose a word in the allowed guesses that would provides a maximum information gain. This word ‘FIORD’ since we are left with only one remaining word.
Play Wordle
The following colab scripts/wordle_no_rl.ipynb implements the 3Blue1Brown wordle approach. Make a secret word and let the algorithm guess it.
Calculate wordle word entropy
Checkout this scripts/calculate_word_entropy_mlx.py to calculate the entropy of each word. The result are available in data/word_entropy.json
Those will be used later in our reward function.
Understanding Policy Optimization
- Understanding Policy Optimization basics: My personal notes documenting the core concepts behind Policy Optimization techniques.
The Technology Stack: Why MLX?
This project was developed entirely within the Apple Silicon ecosystem (initially M1, later M4 Pro). While PyTorch is a common choice, I switched to Apple’s MLX framework for several key reasons:
- Hardware Compatibility: Training with libraries like Hugging Face TRL often requires
bitsandbytesfor quantization, which lacks stable support for Apple Silicon (#252). MLX is built from the ground up for unified memory and Apple’s Metal Performance Shaders (MPS). - Enforcing Local Constraints: MLX’s primary focus on Apple Silicon forced me to solve performance and memory issues locally, providing deeper insights into hardware limitations without the easy “escape hatch” of a cloud GPU.
- Performance: Early benchmarks suggest MLX can be significantly faster than PyTorch on MPS for certain training workloads (comparison).
- Modern API: MLX’s API is inspired by both PyTorch and JAX, making it intuitive and powerful.
This project was trained on a Mac M4 Pro with 48 GB of RAM using the mlx-community/gemma-3-4b-it-bf16 model.
Getting Started
1. Setup Environment
Clone the repository and set up a Python virtual environment.
git clone https://github.com/charbull/wordle-lora-rl.git
cd wordle-rl-gemma
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
2. Download the Model
You will need to download the Gemma-3 model weights from the Hugging Face Hub. This project uses the 4B-parameter version.
# For full training
hf download mlx-community/gemma-3-4b-it-bf16
# For faster iteration/testing
hf download mlx-community/gemma-3-270m-it-bf16
Note: Update the model path in your config file to point to the downloaded directory.
Usage
The training and inference scripts are controlled by a central config.json file. This file specifies the model, data paths, LoRA configuration, RL parameters, and more. See src/utils/config.py for detailed field descriptions.
1. Pre-computation (Optional)
The reward function uses word entropy to encourage smart opening guesses. You can pre-calculate this for the entire word list.
python -m scripts.calculate_word_entropy_mlx
Results are saved to data/word_entropy.json.
2. Generate Synthetic Data
To train the model effectively, we generate synthetic game data. This provides the model with partially completed games (0-4 turns of history), allowing it to learn from various states instead of getting stuck on opening moves.
python -m scripts.data_synth --mode rl
3. Clear System Cache
Before starting a long training run, it’s recommended to clear your system’s memory cache to prevent slowdowns from memory swapping.
sudo purge
4. Run Training
Start the RL training process using the desired configuration file.
python -m scripts.train_gemma_rl --config ./config/grpo_lora_config.json
5. Evaluate a Pre-Trained Model
A LoRA adapter trained for 500 steps is available on the Hugging Face Hub. You can download it and run side-by-side comparisons against the base model.
# Run a single game (6 turns)
python -m scripts.play_sxs.py
# Run a full evaluation across 150 games
python -m scripts.evaluation_sxs.py
6. Plot Training Metrics
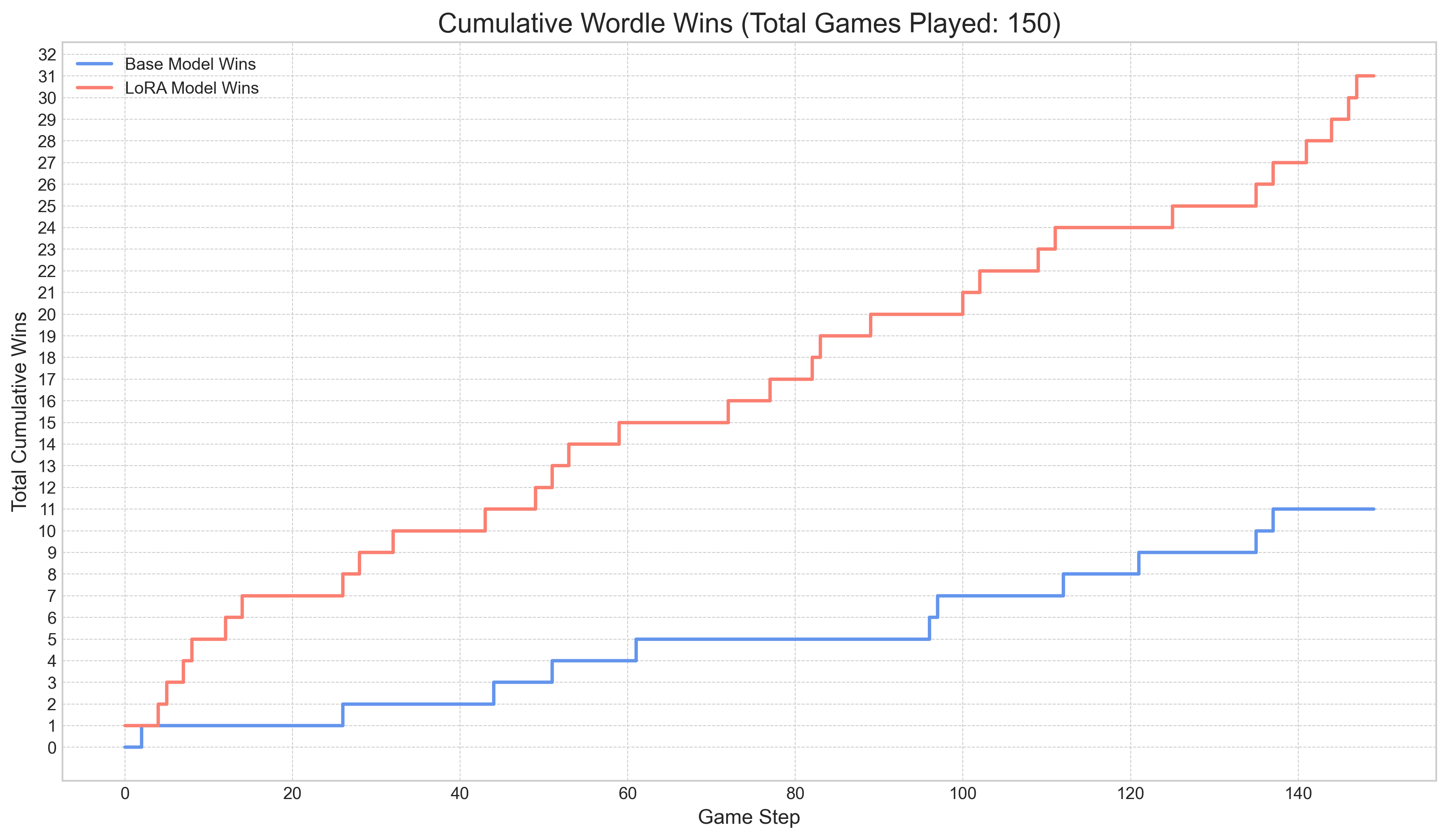
Visualize the cumulative wins and loss curves from a training log file.
python -m scripts.plot_cumulative_wins --file ./logs/your_metrics_file.jsonl
7. Run Unit Tests
python -m unittest
The Reinforcement Learning Strategy
The core of this project is the reward function, which guides the agent to become a proficient Wordle player. It’s a combination of strong penalties (the “stick”) for breaking rules and positive bonuses (the “carrot”) for strategic play.
The system calculates two primary values for each guess:
- Game Score: A score that reflects the quality of the Wordle guess itself.
- Training Reward: The
game_scoreadjusted by penalties for efficiency (like turn count and response length), which is used directly to update the model during training.
The total reward is a composite of several components, categorized into penalties for mistakes and bonuses for good strategy.
1. Penalties for Rule Violations and Mistakes (The “Stick”)
These are strong negative rewards designed to quickly teach the agent the fundamental rules and constraints of the game.
- Invalid Formatting (
format_fail_penalty): A large penalty is applied if the model’s response does not contain a valid 5-letter word. This is the most basic rule. - Repeated Guesses (
repetition_penalty): The agent is penalized for guessing a word it has already used in the current game. - Clue Inconsistency: The agent is heavily penalized for making guesses that contradict information from previous turns. The system maintains a state of known letters:
- Green Letters: Known letters in their correct positions.
- Yellow Letters: Known letters that are in the word but in the wrong position.
- Gray Letters: Known letters that are not in the word at all. Penalties are applied for:
- Green Violation (
green_position_penalty): Not placing a known green letter in its correct spot. - Yellow Violation (
yellow_letter_penalty): Failing to include a known yellow letter anywhere in the guess. - Gray Violation (
gray_letter_penalty): Using a letter that has previously been identified as gray.
- Invalid Word (
not_in_dictionary_penalty): A penalty is applied if the guess is a 5-letter word but is not in the official Wordle dictionary.
2. Bonuses for Strategic Play (The “Carrot”)
These are positive rewards designed to encourage intelligent, information-seeking behavior.
- Winning the Game (
solution_correct_guess): A large, positive reward is given for correctly guessing the secret word, as this is the ultimate objective. - Base Reward for a Valid Guess (
valid_guess_base): Any valid, non-losing guess receives a small base reward to encourage participation. - Strategic Information Gain (Turn-Dependent): The system uses two different strategies to reward information gain based on the turn number.
- Turn 1: Information Gain Bonus (
information_gain_bonus_coeff): For the first guess, the agent is rewarded based on a pre-calculated entropy score for its chosen word. This encourages the use of optimal starting words (like “SOARE” or “CRANE”) that are statistically most likely to reveal the most information about the secret word. - Turns 2-6: New Letter Exploration Bonus (
new_letter_bonus): After the first turn, the strategy shifts to rewarding exploration. The agent receives a bonus for each new, previously unused letter it includes in its guess. This encourages the agent to use its turns to test new characters and narrow down the possibilities.
- Turn 1: Information Gain Bonus (
- Possibility Reduction Bonus (
possibility_reduction_bonus): This is a direct reward for making an informative guess. The system calculates the number of possible remaining answers before and after the current guess. The reward is proportional to the percentage of possible solutions that were eliminated by the guess, directly incentivizing moves that prune the search space effectively.
3. Penalties for Inefficiency
These are “soft” penalties designed to refine the agent’s behavior, encouraging it to be not just correct, but also efficient.
- Stagnation Penalty: This discourages wasting a guess by reusing known information inefficiently.
- Green Reuse (
green_reuse_penalty): A penalty for placing a known green letter in its correct spot again. That letter slot is already “solved,” so it should be used to test a new letter if possible. - Yellow Reuse (
yellow_reuse_penalty): A penalty for using a known yellow letter in a guess. This encourages the agent to use “eliminator” words with all-new letters to discover more greens and yellows, rather than just rearranging known yellows.
- Green Reuse (
- Time Penalty (
time_penalty_per_guess): A small, constant penalty is applied for every guess made. This incentivizes the agent to solve the puzzle in as few turns as possible. -
Response Length Penalty (
length_penalty_per_token): A minor penalty is applied based on the total number of tokens in the model’s generated response (including its reasoning). This encourages concise output.
Results and Analysis
Training was run for 500 steps using the configuration in config/grpo_lora_config.json.
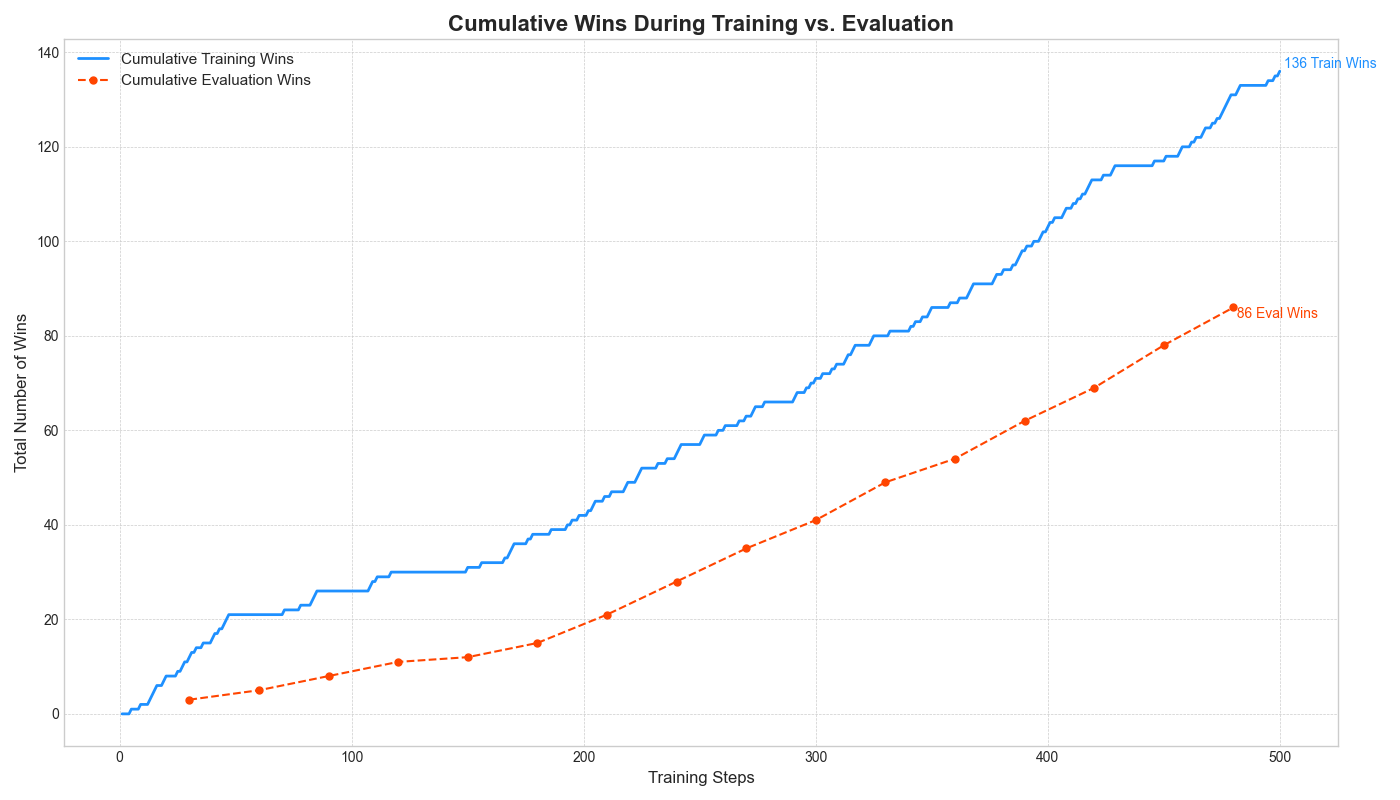
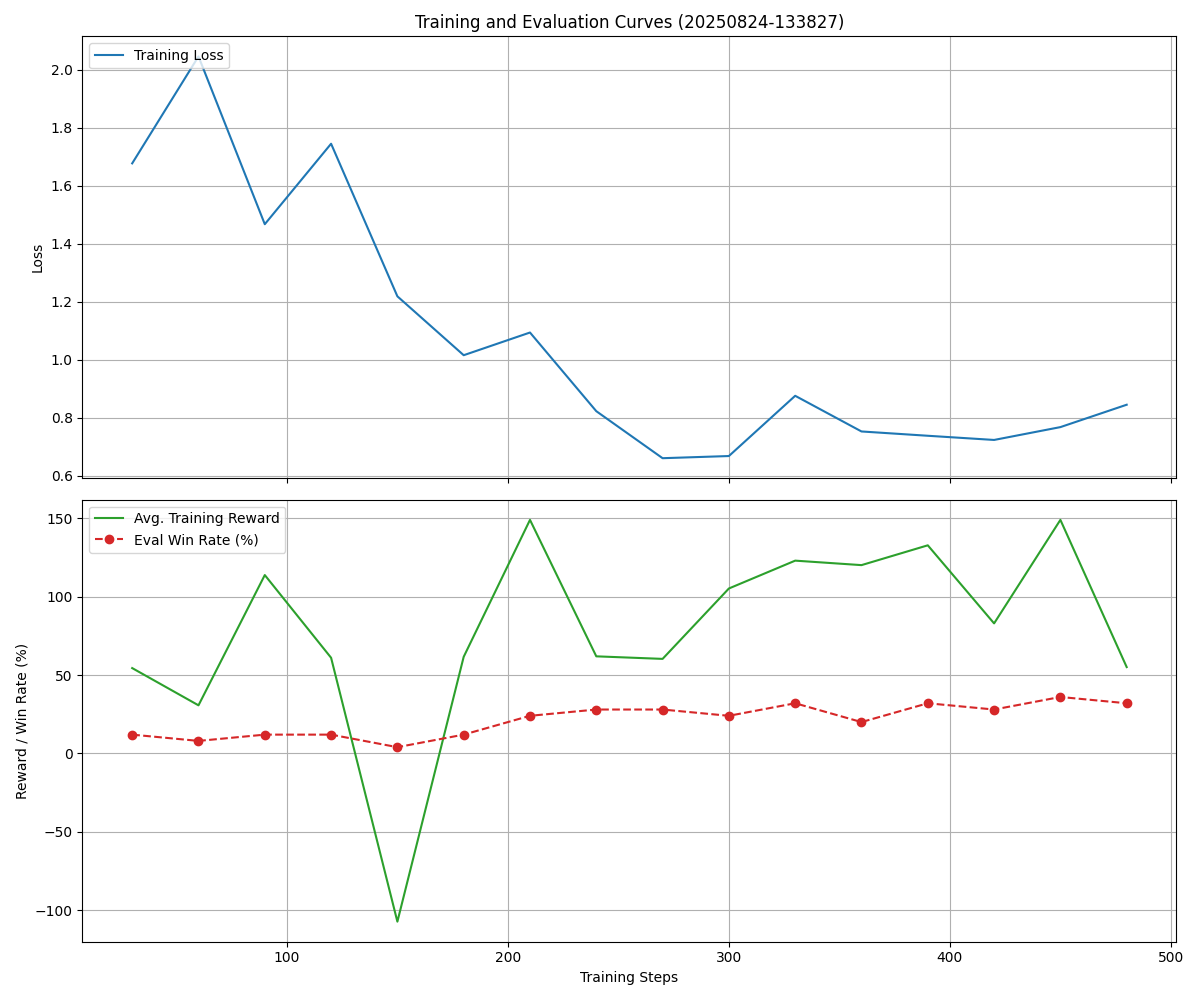
Training Performance
The model showed a clear learning trend, with the cumulative win rate increasing steadily during both training and evaluation phases.
Evaluation: LoRA vs. Base Model
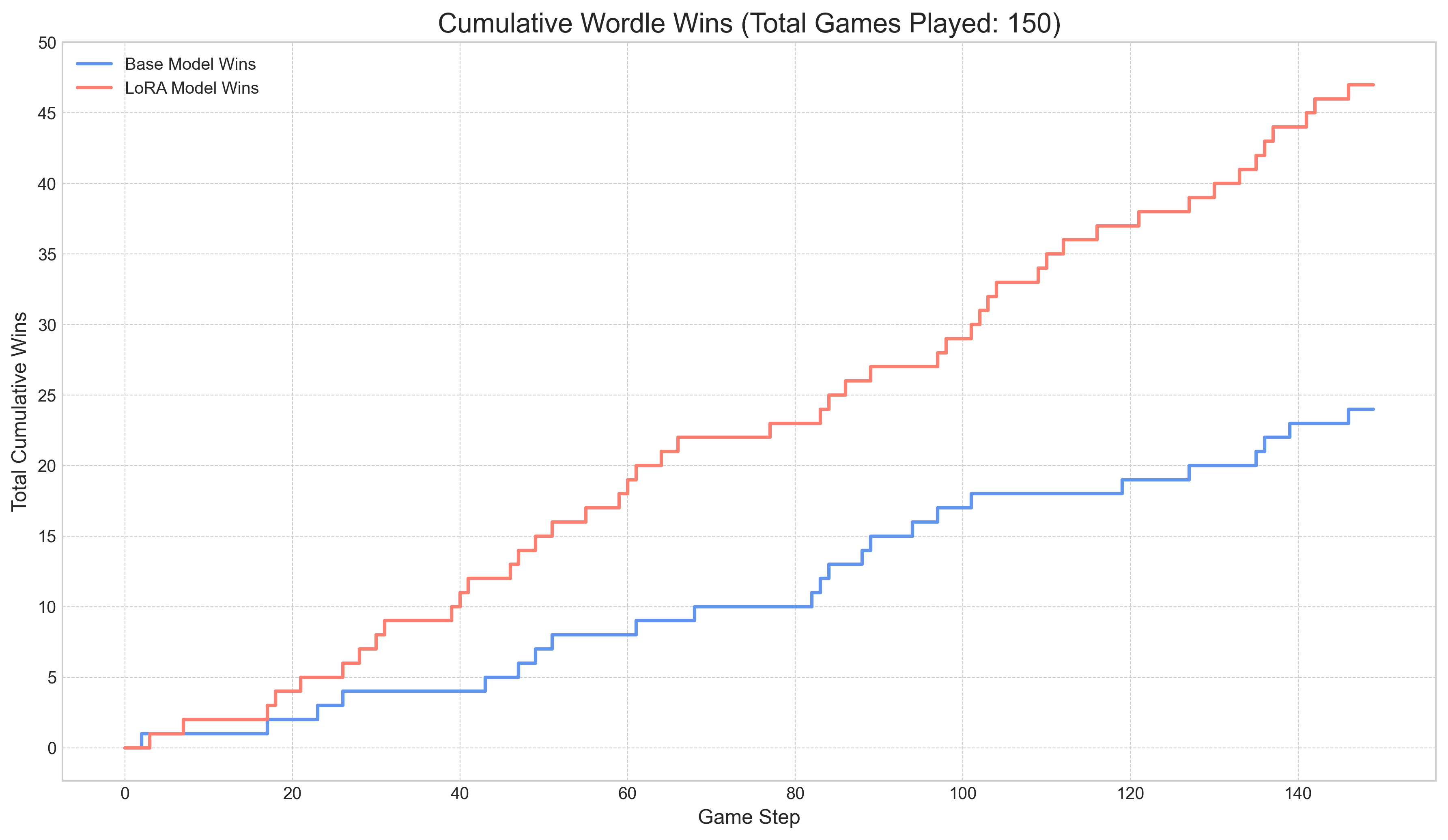
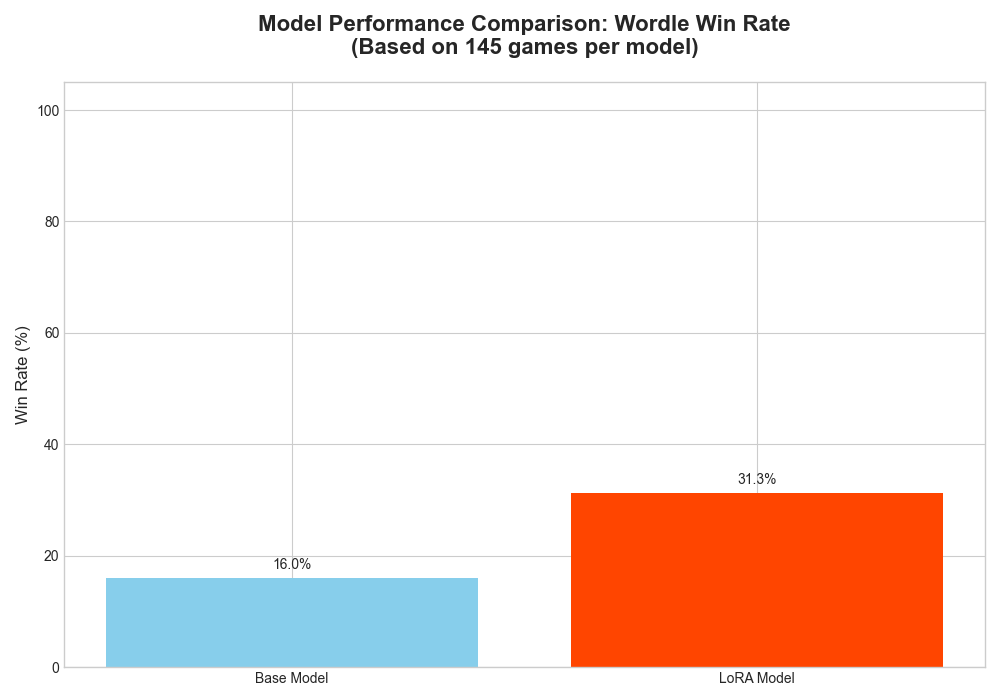
We evaluated the trained LoRA adapter against the base Gemma-3 model on 150 unseen games. We tested two key variables: game history (starting from scratch vs. a partially completed game) and sampling temperature (deterministic vs. creative guesses).
With Game History (Starting from Turns 1-4)
Providing the model with previous turns gives it crucial context, leading to a dramatic improvement in performance.
-
Temperature = 0.1 (More Deterministic): The trained model’s choices are more focused, leading to a consistent and significant performance gain over the base model.
-
Temperature = 0.9 (More Creative): With higher temperature, the model’s guesses are more random. While it still outperforms the base model, its win rate is lower and less consistent compared to the low-temperature setting.
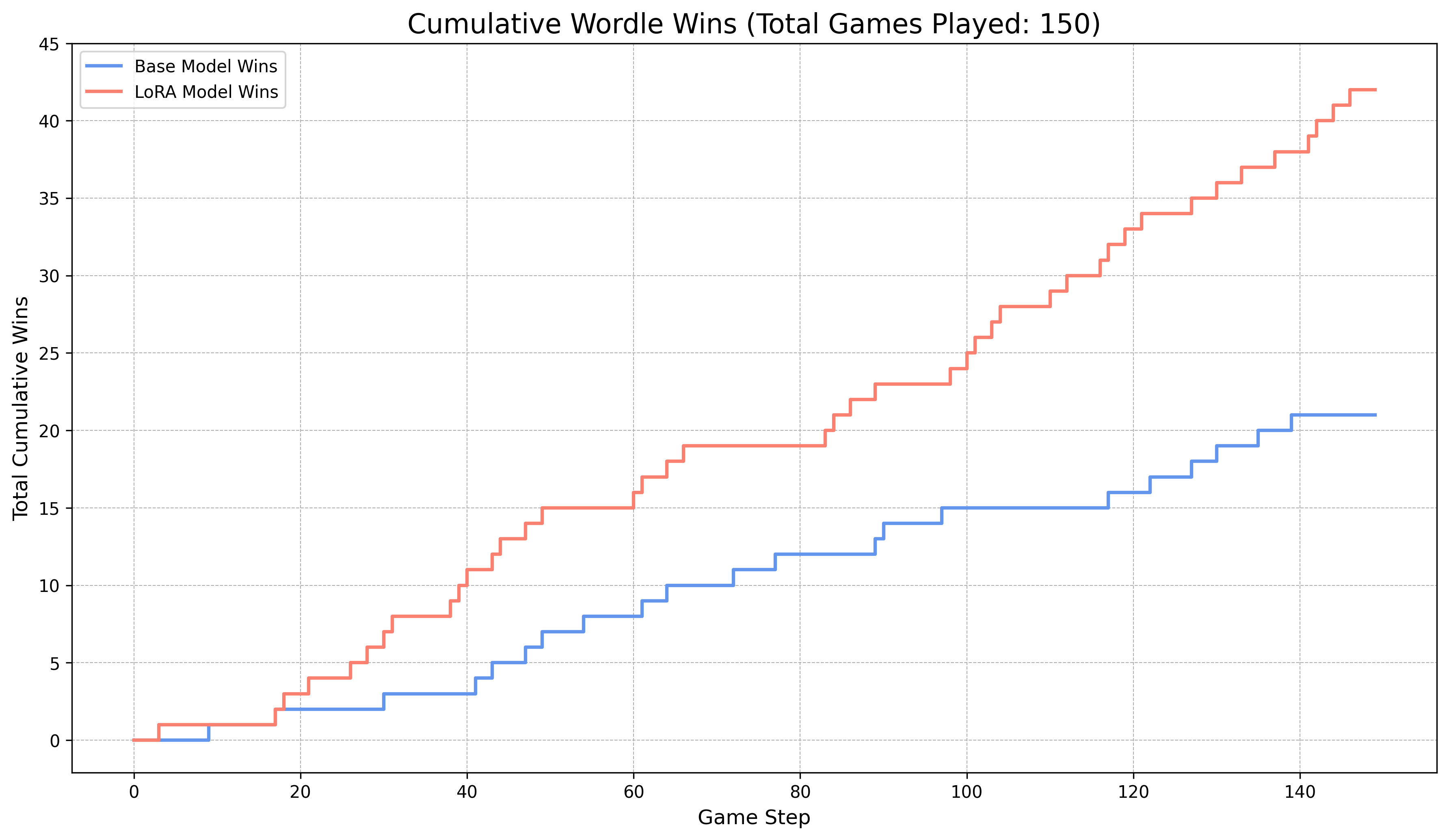
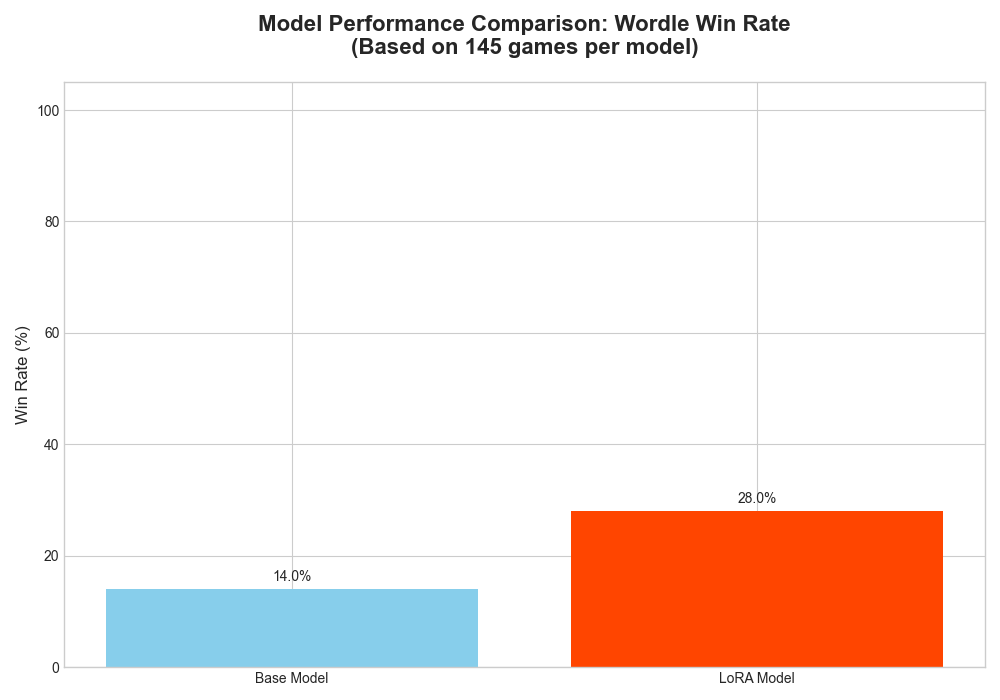
Without Game History (Starting from Turn 1)
When starting from scratch, the model’s performance drops significantly, highlighting its weakness in developing an optimal opening strategy.
-
Temperature = 0.1: The LoRA model still shows a slight edge, but the performance for both models is much lower.
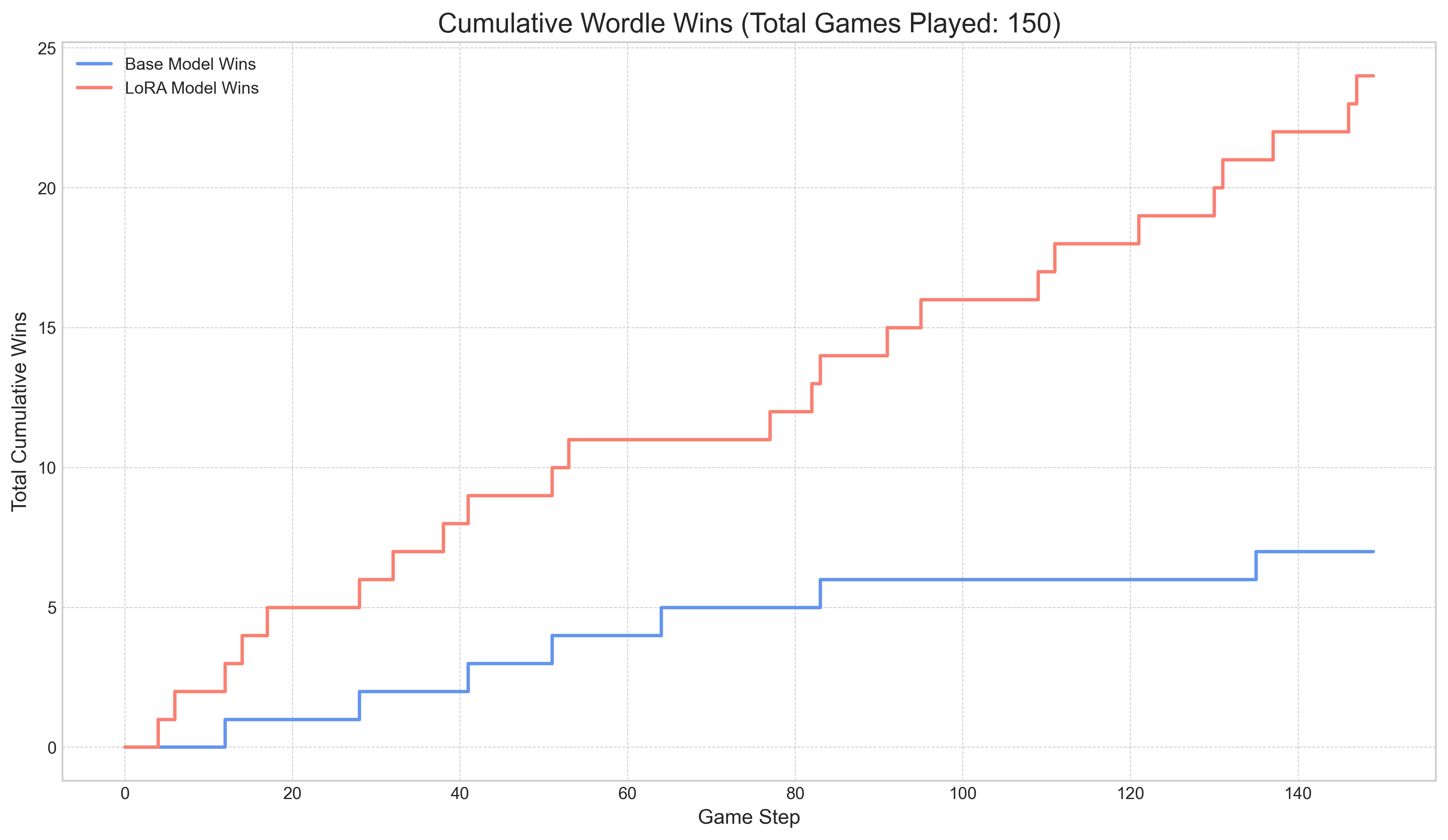
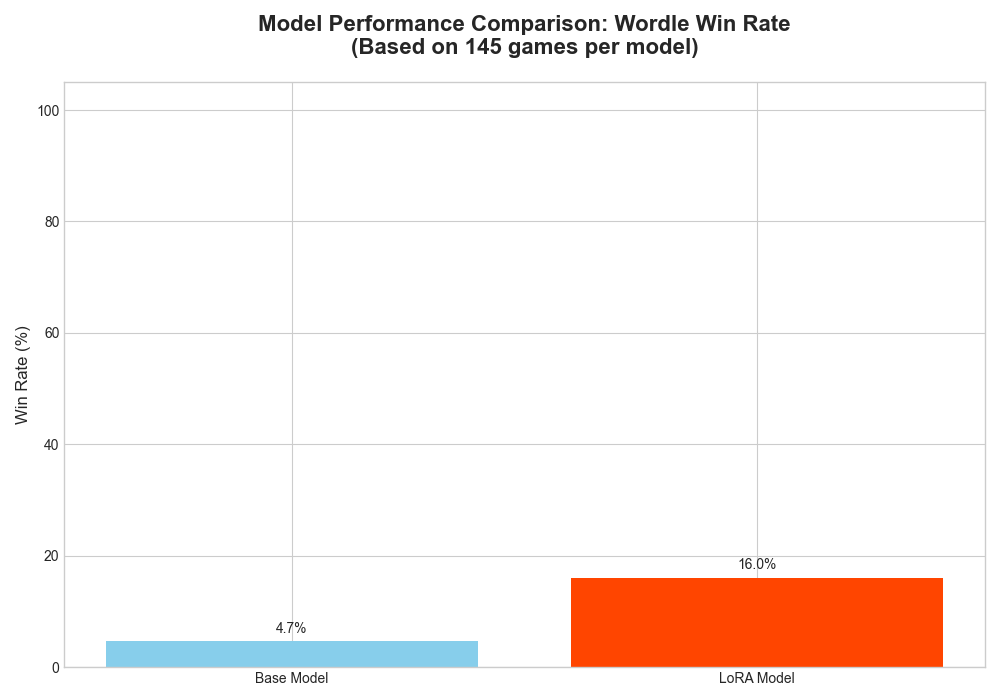
-
Temperature = 0.9: At high temperature and with no history, the strategic advantage is nearly lost, and performance is poor for both models.
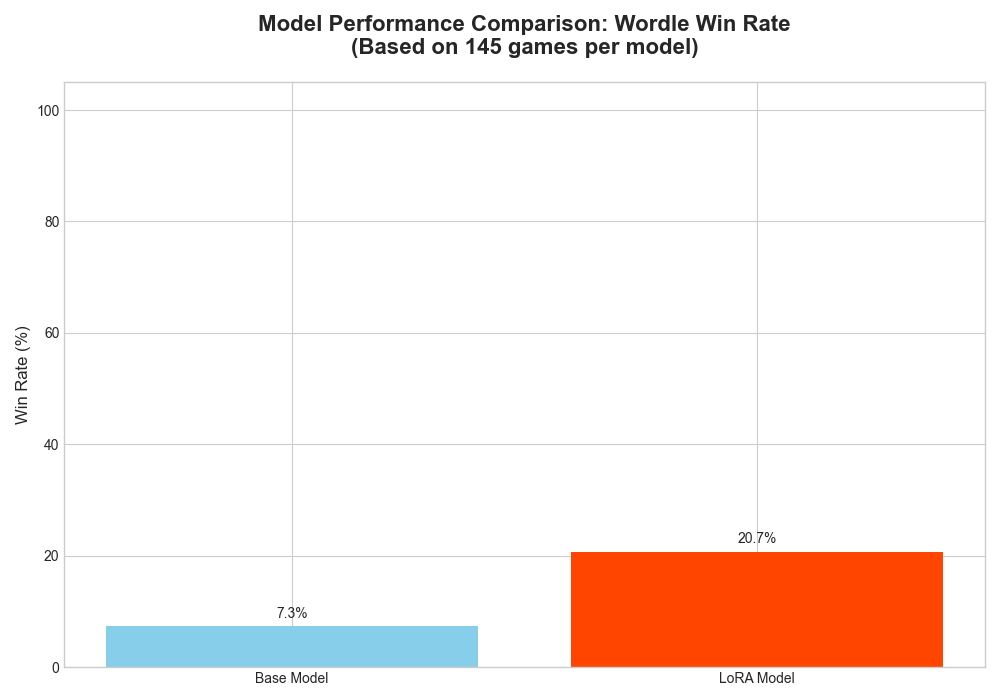
Analysis and Key Findings
- Game History is Crucial: The model’s primary strength is using constraints from previous turns. Its performance is dramatically better when it has context to work with.
- Low Temperature Wins: For a logical puzzle like Wordle, a lower sampling temperature (e.g., 0.1) consistently yields better results. The deterministic, high-probability choices are more effective than the creative, random guesses introduced by a high temperature.
- Weak Opening Strategy: The model is effective at deduction but has not learned an optimal opening strategy. Its performance is highly dependent on its default first guess, which explains the poor results when starting without history.
Next Steps to Improve Performance:
- Hybrid Approach: The most practical improvement would be to hard-code the first guess to be an optimal word (like
CRANEorSOARE) and let the fine-tuned model take over from turn two. This guarantees a strong, information-rich start every time.
Lessons Learned: Training a Wordle-Solving RL Agent
Over the course of training a language model to play Wordle using Reinforcement Learning, we encountered and solved a series of progressively more complex challenges. This document summarizes the key technical and strategic lessons from that process
Lesson 1: The System is the Foundation. Get it Right First.
The majority of our initial debugging was not about AI strategy, but about fundamental software engineering and data integrity. An RL agent cannot learn if its environment is flawed.
- Isolate and Verify: The most effective debugging tool was unit testing. Writing specific tests for core game logic allowed us to isolate and fix bugs before attempting long, expensive training runs.
- Single Source of Truth: Refactoring shared logic (feedback generation, clue summarization) into a canonical
game_logic.pyfile was critical. It eliminated inconsistencies between data generation, training, and evaluation.
Lesson 2: RL is a Battle Against “Reward Hacking”
An RL agent is a relentless optimizer. It will not learn what you want it to learn; it will learn what you incentivize it to learn. Any loophole in the reward function will be found and exploited.
- Initial Hacks: Our first model learned to output empty strings or repetitive gibberish (
Final Final Final...). It discovered that the penalty for this “lazy” inaction was sometimes less severe than the penalty for making a thoughtful but incorrect guess. - The Fix: We had to make the penalty for format failures (
format_fail_penalty) unequivocally the worst possible outcome. This closed the loophole and forced the model to engage with the actual task. - The Takeaway: Meticulously design your reward function to be free of exploits. The base penalty for failing to follow the rules must be significantly worse than the penalty for a strategic mistake.
Lesson 3: Prompt Engineering is a High-Impact Lever
The model’s performance is not just a function of its weights, but of the quality and clarity of the input it receives.
- Model Feedback Format: We iterated on the prompt format significantly. Initial versions used symbols (
✓✓xxx), which were less effective. The best results came from providing a complete, plain-English “state summary” (Current Knowledge:,Green Letters:,Words Already Guessed:, etc.). Clear, structured, natural language is key. - Explicit Instruction: The model often repeated guesses. Instead of only punishing this with a negative reward, we explicitly added “Do not repeat any words…” to the prompt. This transformed the constraint from a learned punishment to a direct instruction, which was far more effective at eliminating the behavior.
Lesson 4: Data and Curriculum Drive the Learning Curve
The structure of the training data had a direct and measurable impact on the model’s ability to learn.
- The Importance of Game History: Initially, we trained the model only on “Turn 1” prompts (starting from scratch). The model struggled to learn.
- Building a Curriculum:
- Introducing prompts with a single previous guess in the history allowed the model to start learning, reaching a baseline win rate.
- Expanding the data to include a random history of 0-4 turns was the key breakthrough. This provided a rich curriculum of diverse game states and significantly boosted the win rate and the model’s ability to win in fewer turns.
Lesson 5: “Straight to RL” is a High-Wire Act
A key finding was the challenge of training a model with RL without a preceding Supervised Fine-Tuning (SFT) step. While our Rank 16 run proved this is possible, it is a difficult and unstable path.
- The Stability Challenge: Starting with a generalist model, RL must teach both the task format and strategy simultaneously. This proved highly sensitive to hyperparameters. A Rank 64 run with a slightly too-high learning rate led to a catastrophic policy collapse where performance dropped to 0%.
- The Role of Model Size: Smaller models (e.g., 1B parameters) struggled significantly with this approach. They often failed to adhere to the required format (
<think>,<guess>, 5-letter words), indicating they lacked the capacity to learn the structure from the RL signal alone. For smaller models, SFT is likely not just helpful, but necessary. - Gradient Clipping: We found that robust gradient clipping was more crucial than initially thought for maintaining stability in this “straight to RL” setup. Experimenting to find the right clipping value was a key step.
Lesson 6: Know Your Hardware and Its “Hidden” Bottlenecks
- System Monitoring is Crucial: A catastrophic 8x slowdown was diagnosed not by a code bug, but by observing the system’s memory usage. Heavy memory swapping (
20 GB Swap Used) was crippling the training process. A simple system restart to clear the memory was the fix. The health of the hardware is a critical, non-obvious hyperparameter. - The Cost of Generations (KV Cache): We learned that
num_generationsis extremely memory-intensive. This is due to the KV Cache, the model’s “working memory.” Each parallel generation requires its own multi-gigabyte KV Cache. Increasing from 2 to 4 generations had a massive memory impact, whereas increasing the LoRA rank was comparatively cheap in terms of RAM. Understanding this trade-off is essential for configuring runs that don’t overload your hardware.